Introduction
Volume of data has been increasing everyday in the globe. Although companies, schools, scientists and institutions need the data, it is not so easy to control and use billion of records that stored on devices. Even if searching a basic word within the records would be so hard without searching techniques or algorithms. In addition, is it enough to use a database management system for filtering, searching, meaning the data? When the amount of data becomes billions level, the most effective database management systems become useless. When a single select question is being applied to the data, it takes hours to get the result. It is obvious that the data will continue to increase. So, we need some additional techniques and tools to manipulate the data more effectively. The new trend is data ware housing.
At the first look, we have to know that data ware house is not related storing the data, it is more relatively with the manipulating of the data. The data that are received from different sources are being processed and some algorithms are applied using online analytical processing applications. It gives us faster selection/filtering times.
In this document, it is tried to give introduction level information.
Anatomy of Data Warehouse
The main purpose of data warehouse is collecting the data that received from heterogeneous, autonomous and distributed external data sources. The reason of this operation classifying the heterogeneous data is providing a platform advanced, complex and efficient analysis of integrated data.
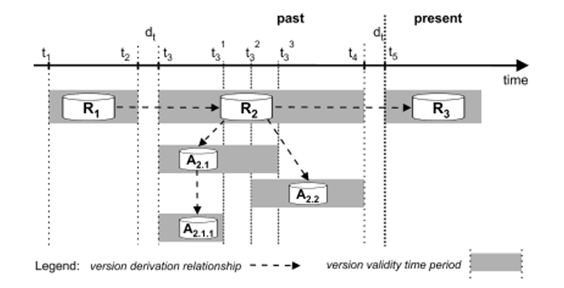
Collecting the data according to user requirements is generally so hard and the data is always changed during the project lifecycle. For this reason, multi version datawarehouse is claimed. The multi version DW is figured out in figure 1.
As you can see from figure1, a dataset existed at the beginning called R1. While the DW is constructed, different ways occur for the future of itself, they are called as version. When dataset reach the version 2, it can go on to version 2.1 or 2.2. This construction is like a general tree in data structures. There are infinite version set.
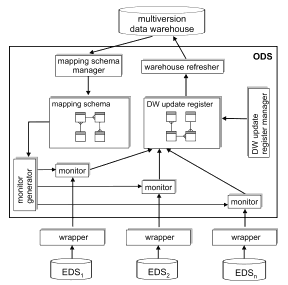
While data is coming from external sources to the system, some small programs monitor incoming data and place them to where it belongs. For different data sources, there are different monitor programs and a monitor generator produces the monitor programs. This is called “change detection framework”. This case is illustrated in figure 2.
DW Development
At the design phase, we face with the main technique for structure, these are “Top-Down” and “Bottom-up”. Buttom-up is more convenient instead of top-down on a single data mart(Jensen-2004). Buttom-up approach gives us a chance to change purpose of the DW while collecting data.
Data Mart
Data mart can be thought atom of DW. It is the smallest meaningful part consists of smaller parts. A department of a company, an organ of a body can be example for data mart. Of course smaller parts can be existed in an organization, but we are thinking our central object will become the data mart. So it is the heart of DW system. We can construct a backbone using data marts and new data marts can be added to the constructed back bone it is called as architecture (Kimbal, 1998).
Requirement Analysis
It is certain that requirement analysis is the one of the most important parts of all projects. In DW systems, requirements can be distinguished into two parts,
- Functional, at the end, what information we are expecting from the DW
- Non-functional, how to use correctly the information that are coming from the DW
In the past most of researches are done on the first subject. Perhaps, the reason is that people are still asking how we will use the information correctly.
Functional Requirements Analysis Techniques
There are three basic approaches about the functional requirement analysis. Names, all pros and cons are figured out in figure 3.
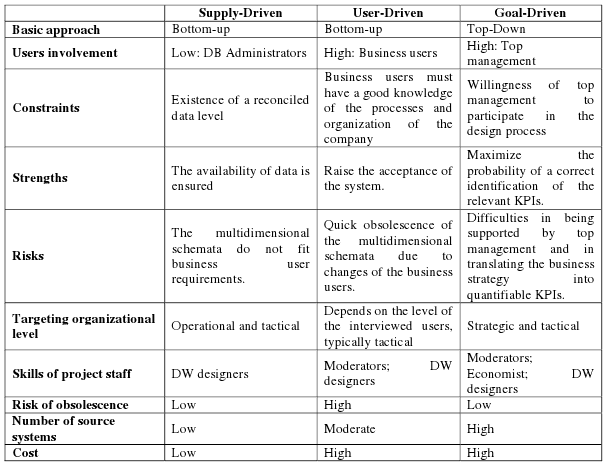
Figure 3 – Functional Requirements Analysis Techniques
Representation of DW
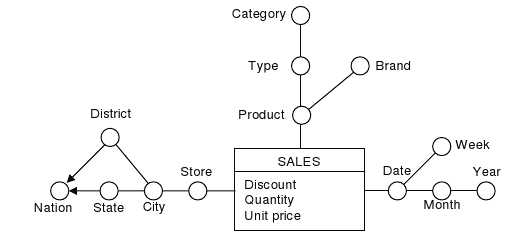
Computer scientists developed some approaches to represent DWs. The most-known is E/R diagrams. E/R has been used and tested for years. Because of this, it is so familiar with computer scientists. It is also so flexible and powerful. However, it does not compensate the requests. A sale fact is modeled in figure 4. It can be examined to understand clearly.
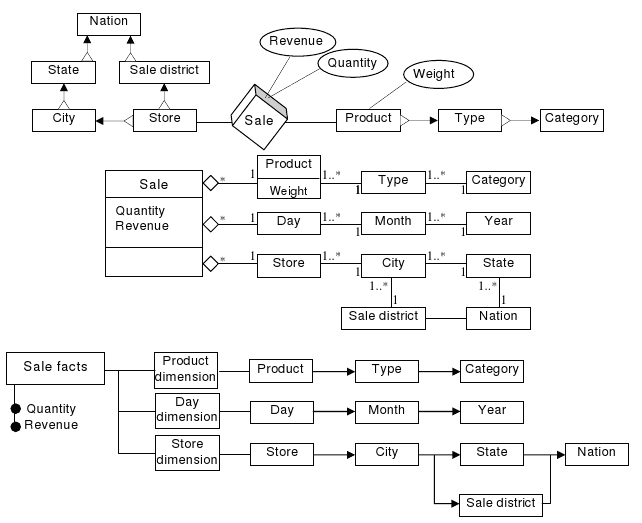
Other technique for representation is “Dimensional Fact Model”. It supports conceptual design effectly. User queries can be intuitively expressed. It supports dialogue between the designer and end user. It provides creating a stable platform. The previous SALE fact is figured out in figure 5.
Indexing Data
Processing large volume data is not so easy without indexes. Online analytical programs generally use star queries for indexing. In order to reduce the execution time of star queries, join indexes are applied to the system. Join indexes typically designed using B-trees.
It is also used bitmap indexes to filter of large volume of data.
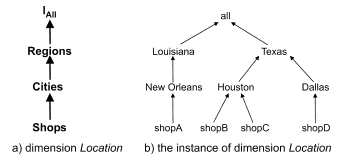
Assume that you have a large dataset of shops and each has its own properties, such as city, region etc. like the example illustrated in figure 6. You want to run a query over the data set. Although it is so easy to find a specific shop within the set, it may be harder to list a set of shops that is located in Houston. In order to make the listing operation faster, we can construct our tree according to our needs. We can classify them thanks to their regions, cities. When we try to run a query over these classes, we will get the result so faster and easier. This is what dw offers us.
Conclusion
It is look like dataware house is not a break news. It is most likely a database management system. Only the restriction is that dw is not insrested in storing data, it is only related with manipulating it. Although it is not a new technology or idea, companies and researchers give it too much attention. Too high costs are paid to develop a system that will give us faster and easier querying. If you are related to databases and love processing large scale data, this area is perfect to give a chance.
